Pause and Pivot: Prioritize Well-Being in a Parallel Universe & Let’s Learn Parallelism Techniques in Data, Model, Pipeline, and Tensor — Or Maybe for Life.
Is it worth it? We should ask this question more often. We have limited time on this earth, and everything we do or desire requires effort. Before investing your sanity, always analyze the situation and be prepared to pivot. As the world has gotten bigger and better, both figuratively and literally, it’s not always necessary to do everything on your own or struggle with mundane things.
Let things go and take a back seat.
Drive is mental.
My biggest struggle is constantly thinking about how we can do better and not stopping until it’s achieved.
This has caused massive burnout and challenged my ability to reason with life.
So, I forced myself to stop going to those comfortable thought patterns. I failed. I got rejected. I got hurt. But I lay there silently, letting time pass and present me with the better future I deserve and dream of dearly.
Hope. Persistence. Being kind to my own lovely self.
Even though everything seems tough, I am moving my needle inward. Learning.
Everyone will talk about AI, even a tarot card reader.
So don’t get overwhelmed.
Let’s make a nice, cushioned seat for ourselves to enjoy the AI ride.
Shall we?
Let me host you for our sweet AI session.
What are we learning today?
Parallelism Techniques in Machine Learning!
Parallelism is crucial in modern machine learning to speed up training and inference of large models. There are several types of parallelism techniques employed to distribute the workload across multiple processors or machines.
In this article, we’ll explore data parallelism, model parallelism, pipeline parallelism, and tensor parallelism, providing brief explanations and code examples for each.
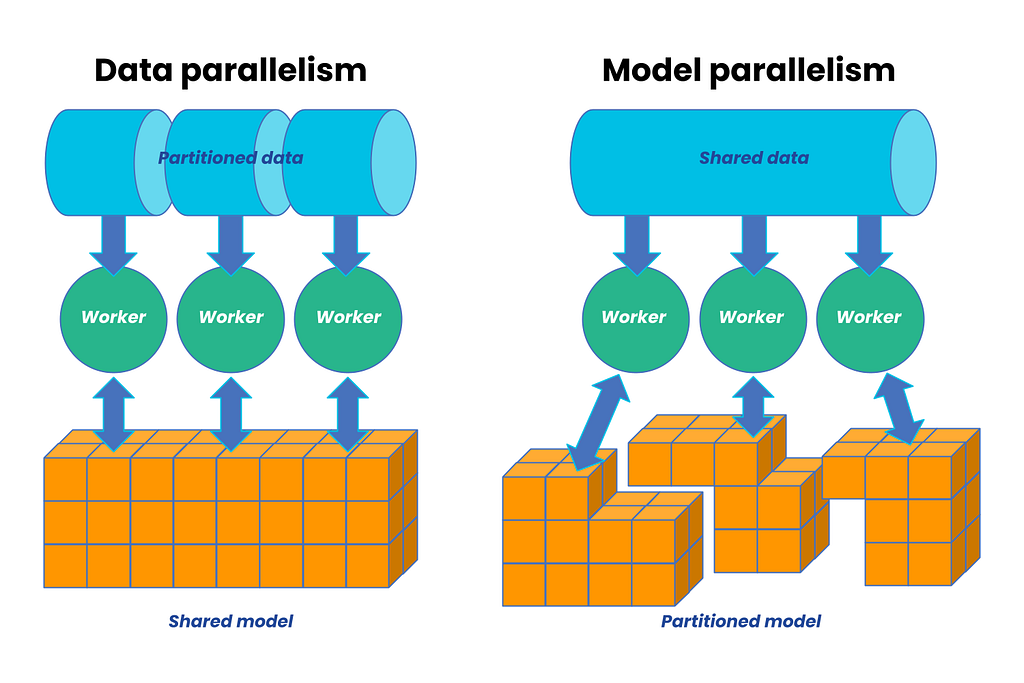
Data Parallelism
Data parallelism involves splitting the training data across multiple processors or machines. Each processor works on a different subset of the data but uses the same model. Gradients are calculated in parallel and then aggregated to update the model.
Code Example
Here’s a simple example using PyTorch’s DataParallel module:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# Define a simple model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# Create a dataset and dataloader
data = torch.randn(1000, 10)
labels = torch.randn(1000, 1)
dataset = TensorDataset(data, labels)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# Create the model and wrap it in DataParallel
model = SimpleModel()
model = nn.DataParallel(model)
# Define loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training loop
for epoch in range(10):
for inputs, targets in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
Model Parallelism
Model parallelism splits the model itself across multiple processors. This is useful when the model is too large to fit into the memory of a single processor.
Code Example
Here’s an example using PyTorch to split a simple model across two GPUs:
import torch
import torch.nn as nn
# Define a model with parts on different GPUs
class ModelParallelModel(nn.Module):
def __init__(self):
super(ModelParallelModel, self).__init__()
self.fc1 = nn.Linear(10, 50).to('cuda:0')
self.fc2 = nn.Linear(50, 1).to('cuda:1')
def forward(self, x):
x = x.to('cuda:0')
x = self.fc1(x)
x = x.to('cuda:1')
x = self.fc2(x)
return x
# Create the model
model = ModelParallelModel()
# Example input
input = torch.randn(32, 10).to('cuda:0')
output = model(input)
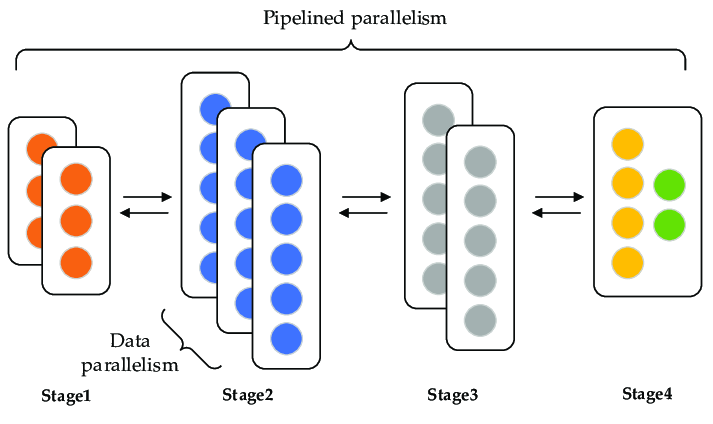
Pipeline Parallelism
Pipeline parallelism divides the model into stages, where each stage runs on a different processor. The data flows through these stages in a pipeline fashion.
Code Example
Here’s an example using PyTorch’s pipeline parallelism:
import torch
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe
# Define a sequential model
class Stage1(nn.Module):
def __init__(self):
super(Stage1, self).__init__()
self.fc1 = nn.Linear(10, 50)
def forward(self, x):
return self.fc1(x)
class Stage2(nn.Module):
def __init__(self):
super(Stage2, self).__init__()
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
return self.fc2(x)
# Create the pipeline
model = nn.Sequential(Stage1(), Stage2())
model = Pipe(model, chunks=2)
# Example input
input = torch.randn(32, 10)
output = model(input)
Tensor Parallelism
Tensor parallelism splits individual tensors (e.g., weights) across multiple processors. This is useful for distributing the computation of large matrix operations.
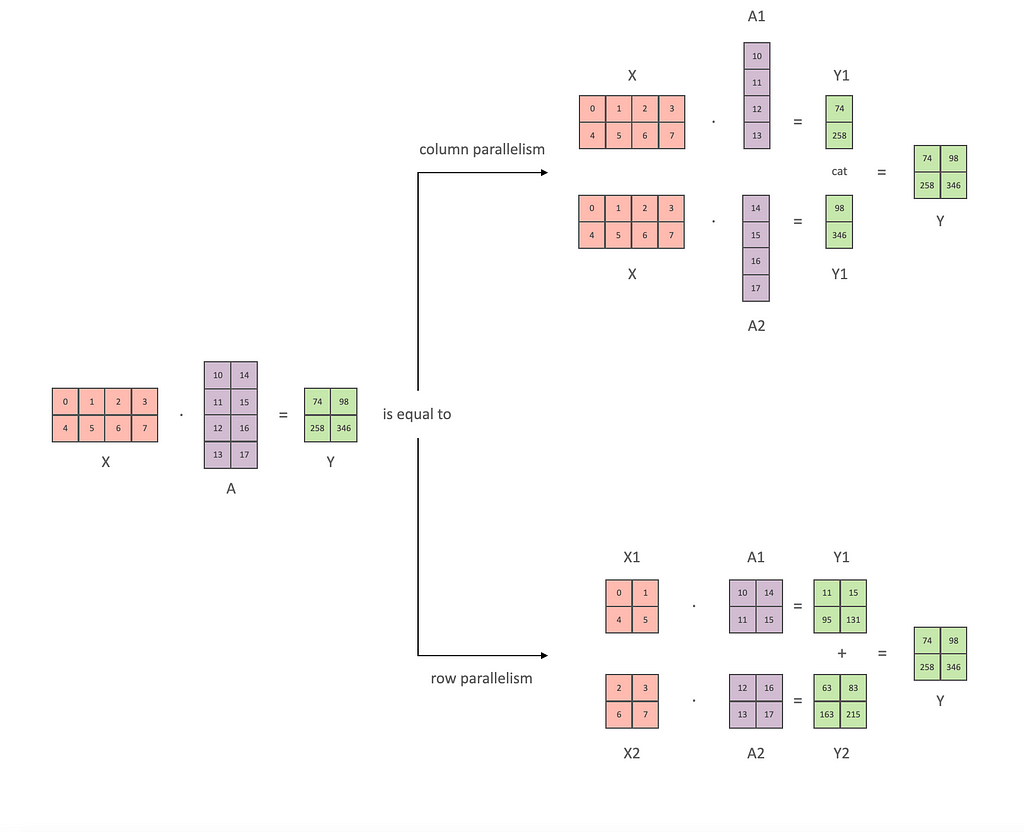
Code Example
Here’s a simplified example using tensor parallelism in a custom layer:
import torch
import torch.nn as nn
class TensorParallelLinear(nn.Module):
def __init__(self, input_size, output_size, num_devices):
super(TensorParallelLinear, self).__init__()
self.num_devices = num_devices
self.weights = nn.ParameterList([
nn.Parameter(torch.randn(input_size // num_devices, output_size).to(f'cuda:{i}'))
for i in range(num_devices)
])
def forward(self, x):
# Split input across devices
chunks = x.chunk(self.num_devices, dim=1)
outputs = [torch.matmul(chunk.to(f'cuda:{i}'), self.weights[i]) for i, chunk in enumerate(chunks)]
return torch.cat(outputs, dim=1)
# Example use
model = TensorParallelLinear(10, 20, num_devices=2)
input = torch.randn(32, 10)
output = model(input)
Interesting stuff… Can we dive deeper? Absolutely!
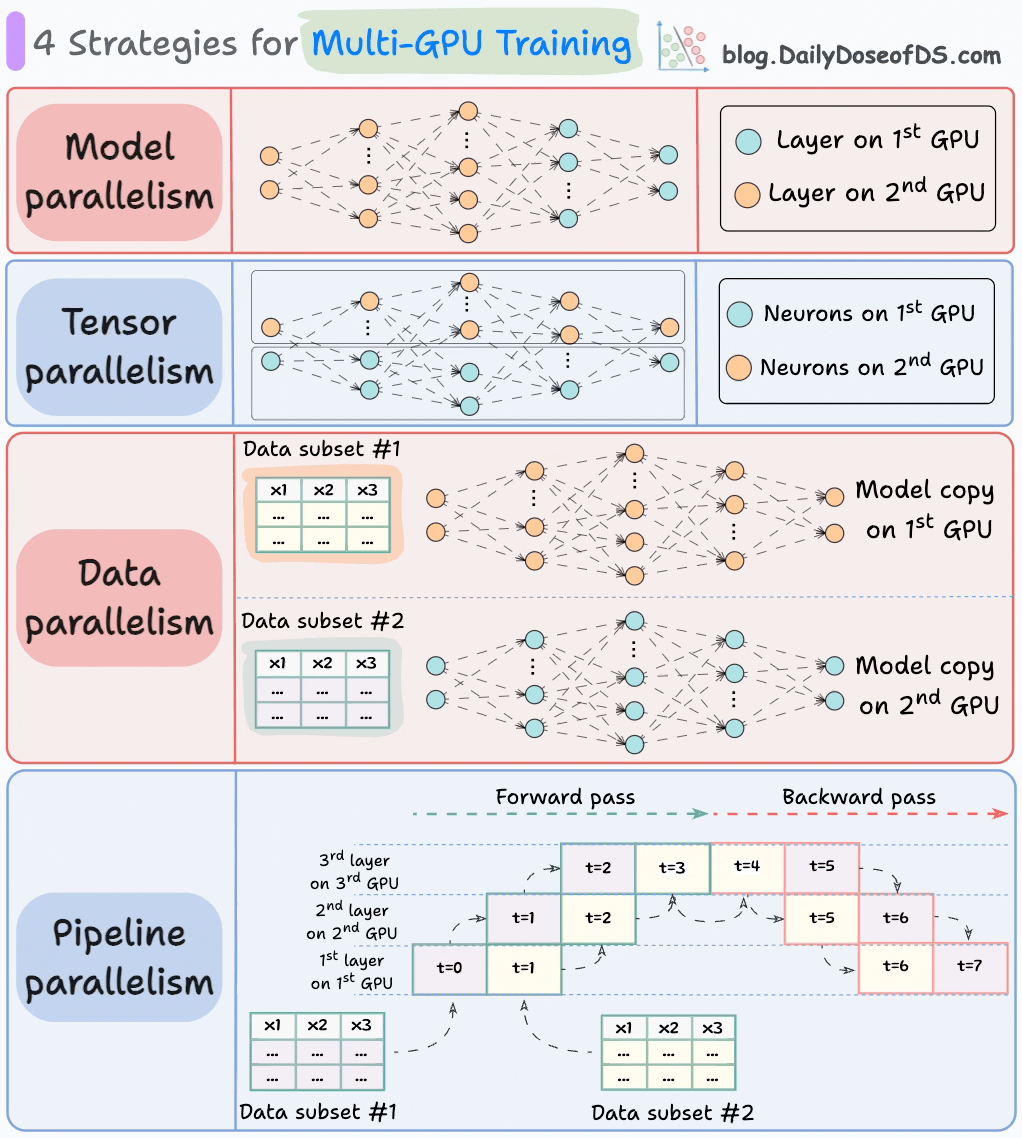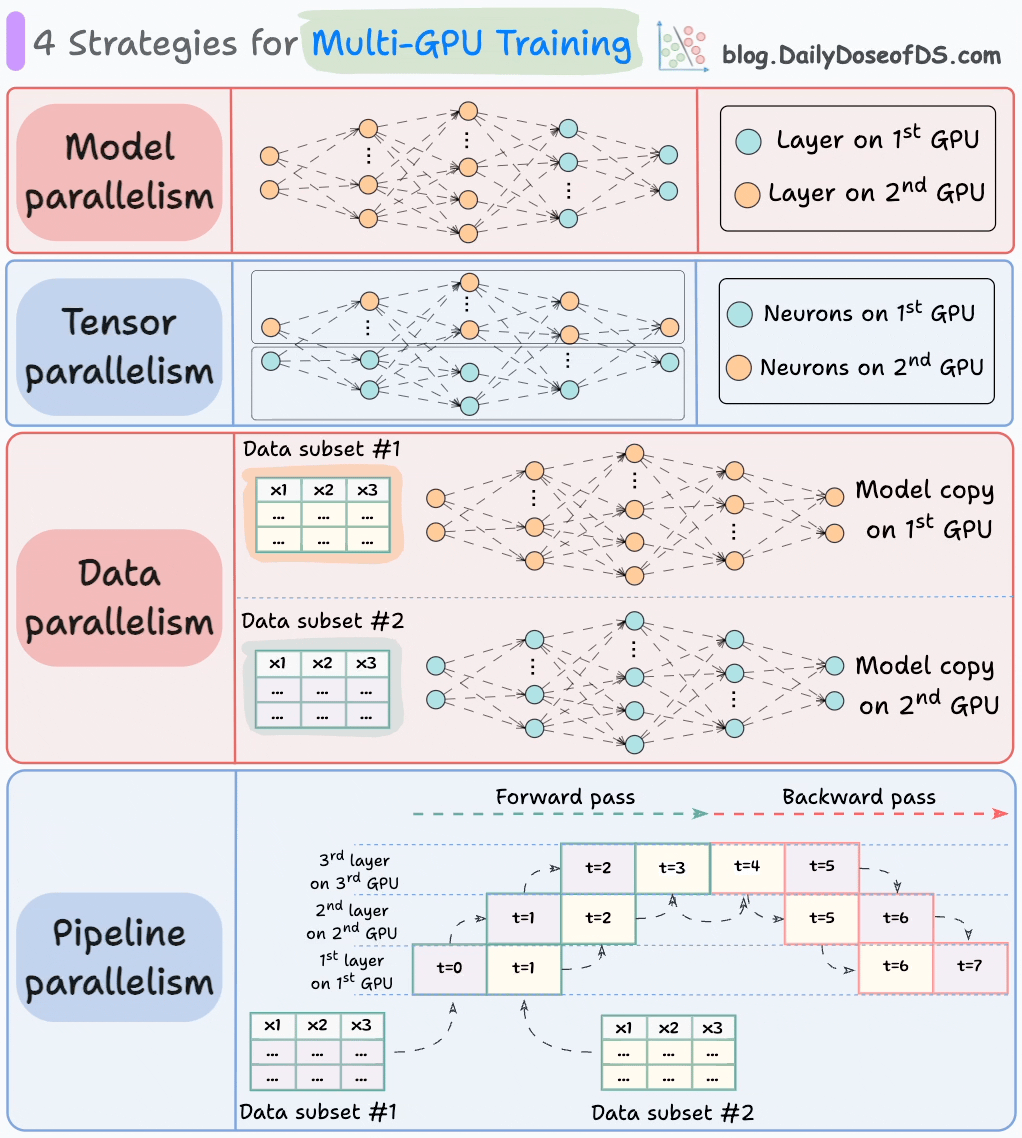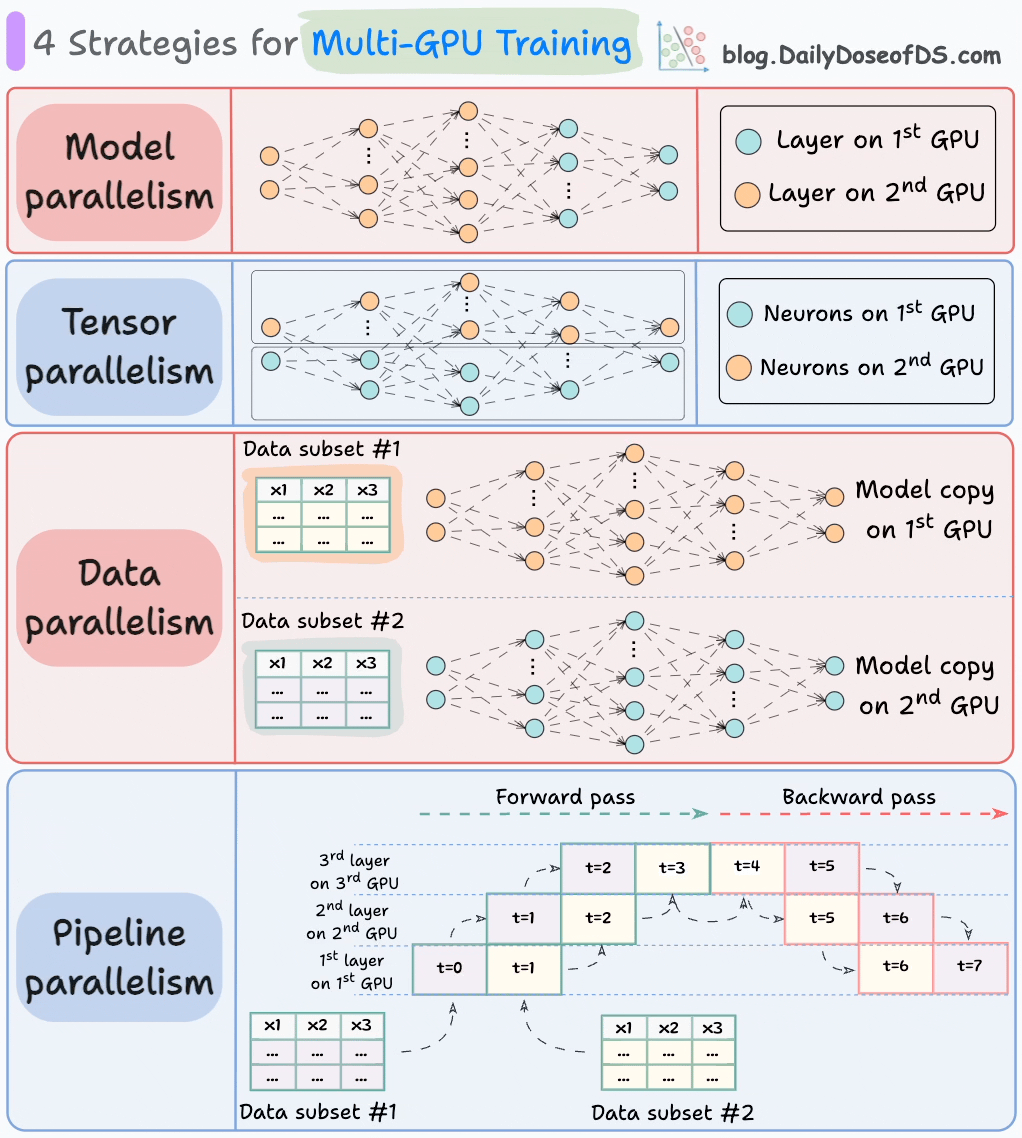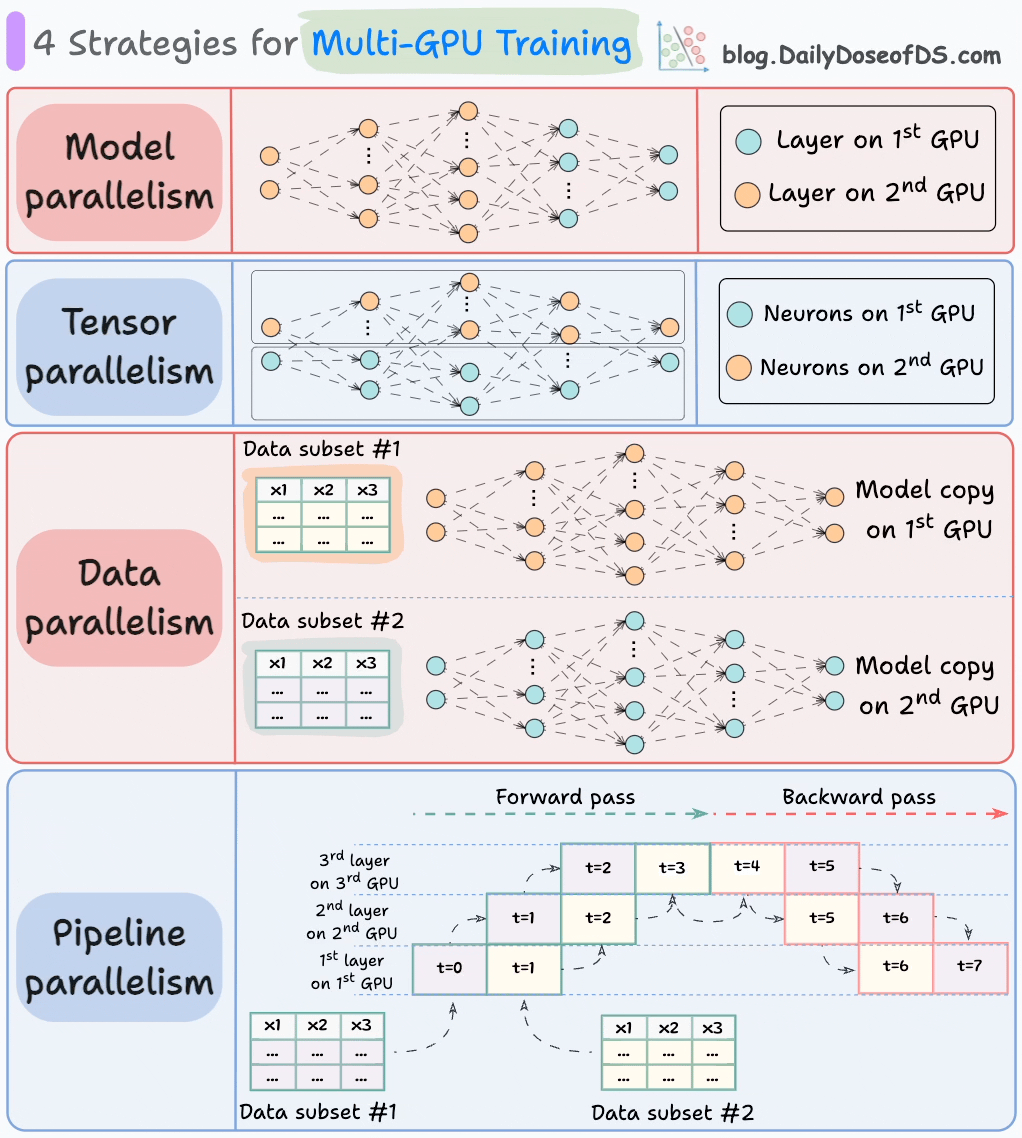
Each type of parallelism in machine learning has its specific use cases based on the nature of the data, model size, and computational requirements.
Here are some real-world examples for each type:
Data Parallelism
Use Case: Image Classification with Convolutional Neural Networks (CNNs)
In tasks like image classification, where the model architecture (e.g., ResNet, VGG) can be replicated across multiple GPUs, data parallelism is highly effective. Each GPU processes a different subset of the images in the dataset, computing gradients in parallel, which are then aggregated to update the model parameters.
Example: Training a ResNet model on a large-scale image dataset like ImageNet, where the dataset is divided among multiple GPUs to speed up training.
# Example setup in PyTorch using DataParallel
model = torchvision.models.resnet50(pretrained=False)
model = nn.DataParallel(model)
Model Parallelism
Use Case: Natural Language Processing with Transformer Models
When dealing with extremely large models like GPT-3 or BERT, which may not fit into the memory of a single GPU, model parallelism is used. Parts of the model, such as layers of a Transformer, are distributed across multiple GPUs.
Example: Training GPT-3, where different layers or components of the model are split across several GPUs to manage memory constraints and computational load.
# Example setup in PyTorch for a Transformer model
class ModelParallelTransformer(nn.Module):
def __init__(self):
super(ModelParallelTransformer, self).__init__()
self.layer1 = nn.TransformerEncoderLayer(d_model=512, nhead=8).to('cuda:0')
self.layer2 = nn.TransformerEncoderLayer(d_model=512, nhead=8).to('cuda:1')
# Forward pass code here
Pipeline Parallelism
Use Case: Complex Deep Learning Models in Autonomous Driving
Autonomous driving systems often require complex deep learning models with multiple stages, such as perception, prediction, and planning. Pipeline parallelism can be used to process data through these stages in a sequential manner, where each stage runs on different hardware.
Example: In an autonomous vehicle, data from sensors (cameras, LiDAR) is processed in stages, with each stage (object detection, lane detection, path planning) running on different processors or GPUs.
# Example setup using PyTorch's Pipeline parallelism
class PerceptionStage(nn.Module):
def __init__(self):
super(PerceptionStage, self).__init__()
self.detector = nn.Conv2d(3, 16, 3, 1).to('cuda:0')
class PlanningStage(nn.Module):
def __init__(self):
super(PlanningStage, self).__init__()
self.planner = nn.LSTM(input_size=100, hidden_size=50).to('cuda:1')
# Create pipeline
model = nn.Sequential(PerceptionStage(), PlanningStage())
model = Pipe(model, chunks=2)
Tensor Parallelism
Use Case: Large-Scale Matrix Factorization for Recommendation Systems
In recommendation systems, tensor operations like matrix factorization can become very large. Tensor parallelism helps by splitting these large matrices across multiple processors to distribute the computational load.
Example: Implementing matrix factorization for collaborative filtering in a recommendation system, where the user-item interaction matrix is too large to fit into the memory of a single GPU.
# Example setup in PyTorch for a custom tensor-parallel layer
class TensorParallelMatrixFactorization(nn.Module):
def __init__(self, num_users, num_items, num_factors, num_devices):
super(TensorParallelMatrixFactorization, self).__init__()
self.num_devices = num_devices
self.user_factors = nn.ParameterList([
nn.Parameter(torch.randn(num_users // num_devices, num_factors).to(f'cuda:{i}'))
for i in range(num_devices)
])
self.item_factors = nn.ParameterList([
nn.Parameter(torch.randn(num_items // num_devices, num_factors).to(f'cuda:{i}'))
for i in range(num_devices)
])
def forward(self, user_ids, item_ids):
user_chunks = user_ids.chunk(self.num_devices, dim=0)
item_chunks = item_ids.chunk(self.num_devices, dim=0)
output = sum(
torch.matmul(user_chunks[i].to(f'cuda:{i}'), self.item_factors[i].T)
for i in range(self.num_devices)
)
return output
# Example use
model = TensorParallelMatrixFactorization(num_users=10000, num_items=5000, num_factors=50, num_devices=2)
user_ids = torch.randint(0, 10000, (32,))
item_ids = torch.randint(0, 5000, (32,))
output = model(user_ids, item_ids)
Conclusion
Parallelism techniques such as data parallelism, model parallelism, pipeline parallelism, and tensor parallelism are essential for efficiently training and deploying large machine learning models. Each method has its use cases and advantages, and the choice of parallelism technique depends on the specific requirements of the task and the architecture of the model.
In summary, these parallelism techniques are essential for efficiently training and deploying machine learning models, especially as model sizes and data volumes continue to grow.
Follow for more things on AI! The Journey — AI By Jasmin Bharadiya
In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: CoFeed | Differ
- More content at PlainEnglish.io
Pause and Pivot: Prioritize Well-Being in a Parallel Universe & Let’s Learn Parallelism Techniques… was originally published in Artificial Intelligence in Plain English on Medium, where people are continuing the conversation by highlighting and responding to this story.
* This article was originally published here