Prompt engineering sucks.
It is by far the most tedious part about working with large language models. These models are finnicky, and a seemingly innocuous change to the prompt can cause widely different results. I’m sick of the manual tweaking, the unsystematic changes, and the headache associated with manual prompt engineering…
Just so we’re on the same page, prompt engineering refers to the crafting and refining of the instructions (prompts) given to an AI model to elicit the desired responses. It requires a deep understanding of the model’s behavior and a lot of trial and error to get consistent and accurate outputs.
But the traditional, manual process of improving your prompts sucks. So I’m making an automated prompt optimizer.
This article will be a multi-part series. The first half of the article will be an overview of my general approach. I will discuss what I’ve done to get the ground truths, which are an important part in the optimization process.
The next part of the article will be about the optimization phase. It will discuss what I plan to do to improve my “AI Stock Screener”, an LLM-Powered feature within the NexusTrade platform.
This work is important because it could allow us to spend less time on manual prompt tweaking (which doesn’t guarantee improved performance) and more time focusing on actual business use-cases for large language models.
I just tried out the new GPT-4o mini model and am BEYOND Impressed
Overview of my approach: Automated Prompt Optimization
EvoPrompt – Evolutionary Algorithms Meets Prompt Engineering. A Powerful Duo
My approach is inspired by a paper called EvoPrompt, a framework for automated prompt optimization. This framework uses evolutionary-inspired algorithms that mimic the process of natural selection to iteratively improve solutions.
Evolutionary algorithms are a class of optimization algorithms inspired by Charles Darwin’s theory of evolution. There are four phases to them:
- Initialization: How the initial population is generated
- Selection: How individuals in the populated are “selected” to reproduce, with more fit individuals being more likely to be selected
- Crossover (or recombination): How we choose to combine the “genes” of our parents to create new offspring (or solutions)
- Mutation: An unexpected change in an offspring that can have positive or detrimental effects on its fitness
- Evaluation: How we calculate the fitness of our offspring
In order to utilize this algorithm for prompt optimization, we need a population of input/output pairs that we can use during the process. One segment will be for training the model, and the other segment will be for evaluating it. Here’s how we’ll get these examples.
From Beaks to Bytes: Genetic Algorithms in Trading, Investing, and Finance
Phase 1: Getting the ground truth
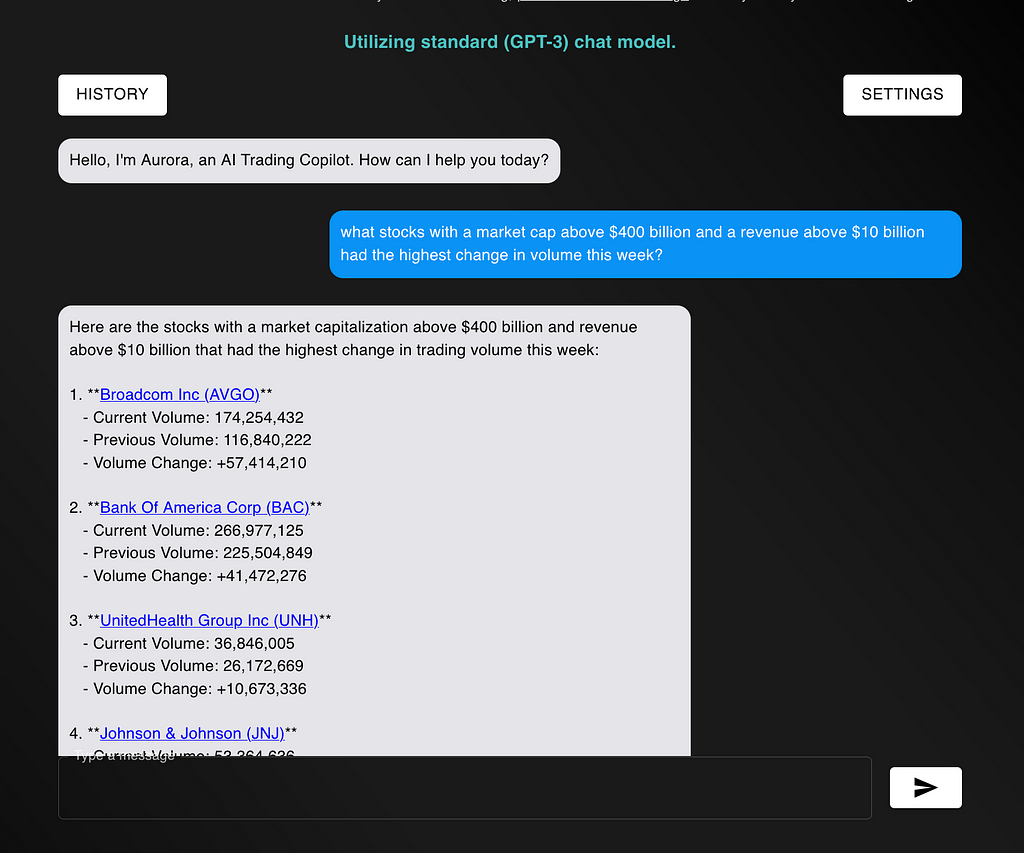
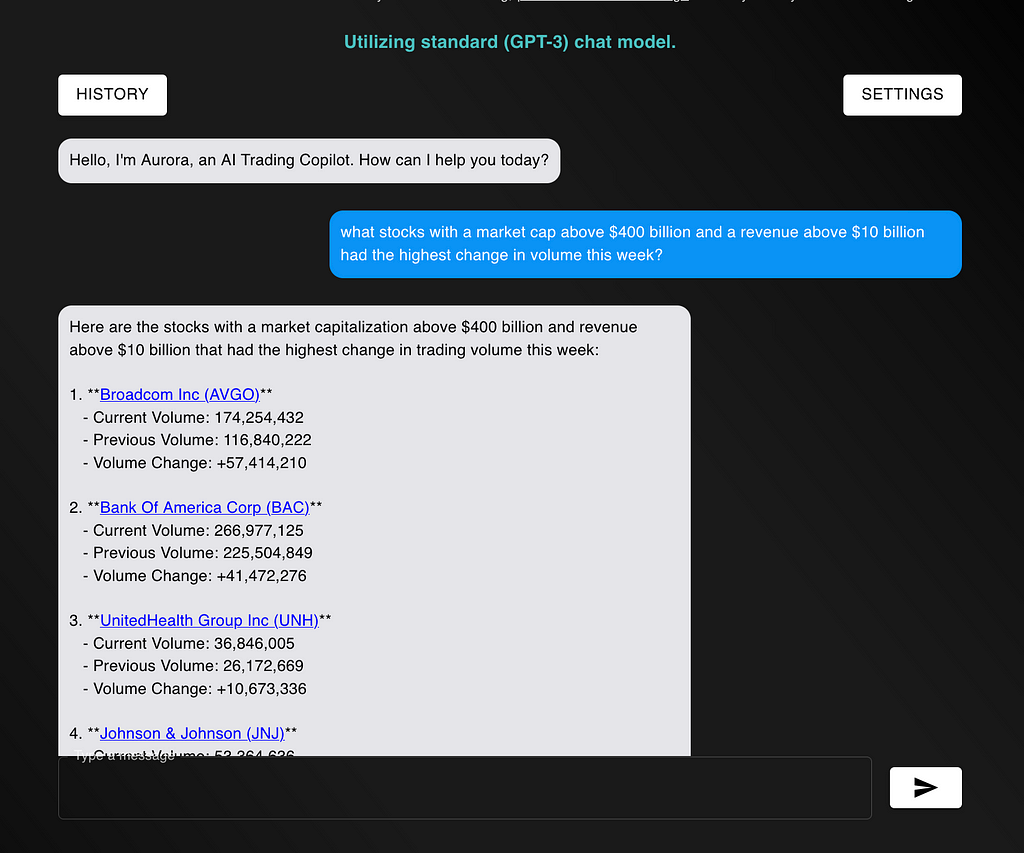
The prompt that I will optimize is my AI-Powered stock screener. Given natural language inputs, the screener will find the stock or stocks that match your criteria.
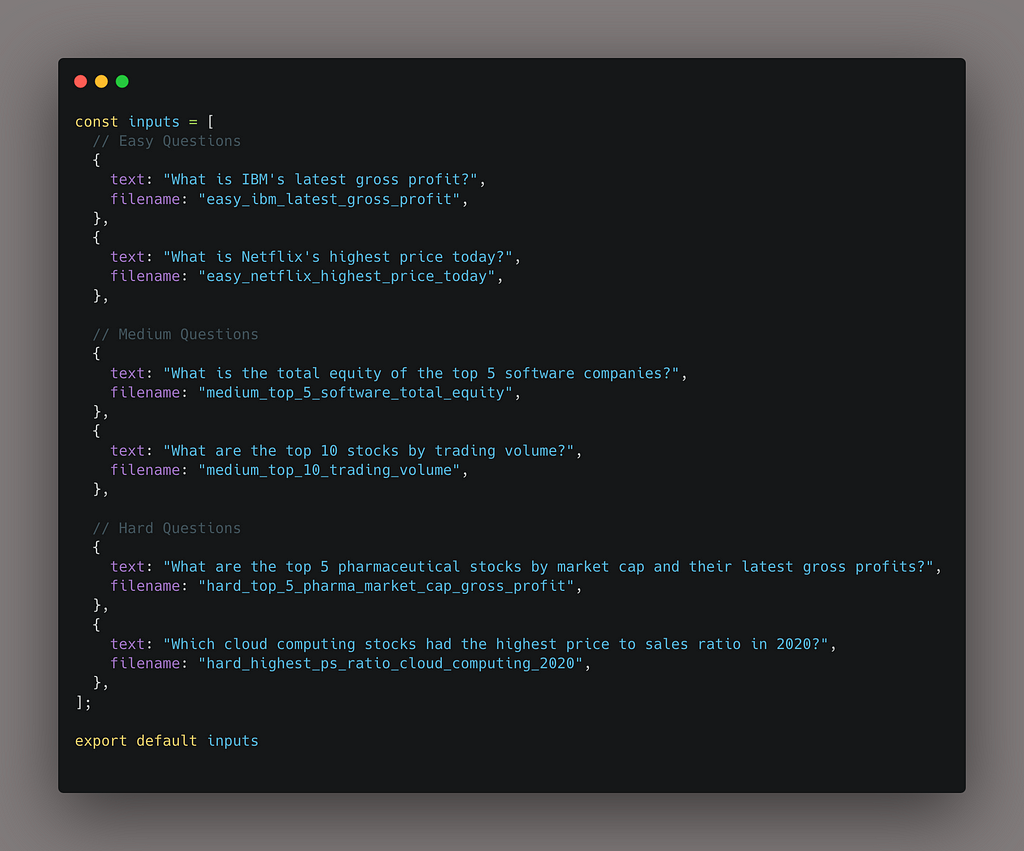
Some example inputs are:
- (Easy) What is IBM’s latest gross profit?
- (Medium) What is the total equity of the top 5 software companies?
- (Hard) What 10 companies with a market cap of $100 billion or more had the lowest price to free cash flow ratio on June 16th 2021?
My approach will be relatively straightforward. I gathered a list of 60 questions and retrieved answers to those questions. I’ll save the question/answer pairs onto my computer using the following directory structure:
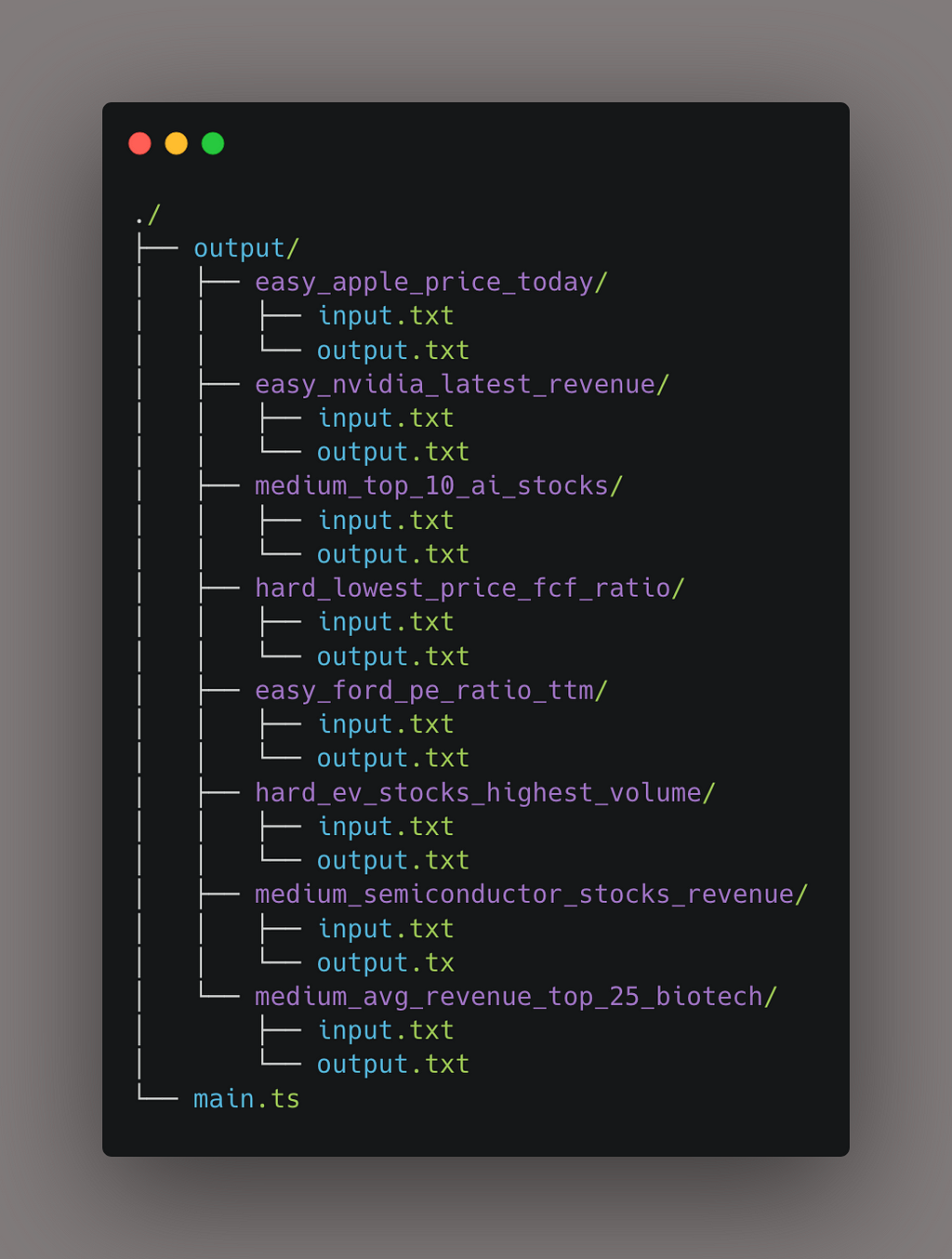
Mathematically Improve Your Trading Strategy: An In-Depth Guide
Script to Populate Input/Output Pairs
To generate all of the outputs from the inputs, I’m also using an AI-driven approach.
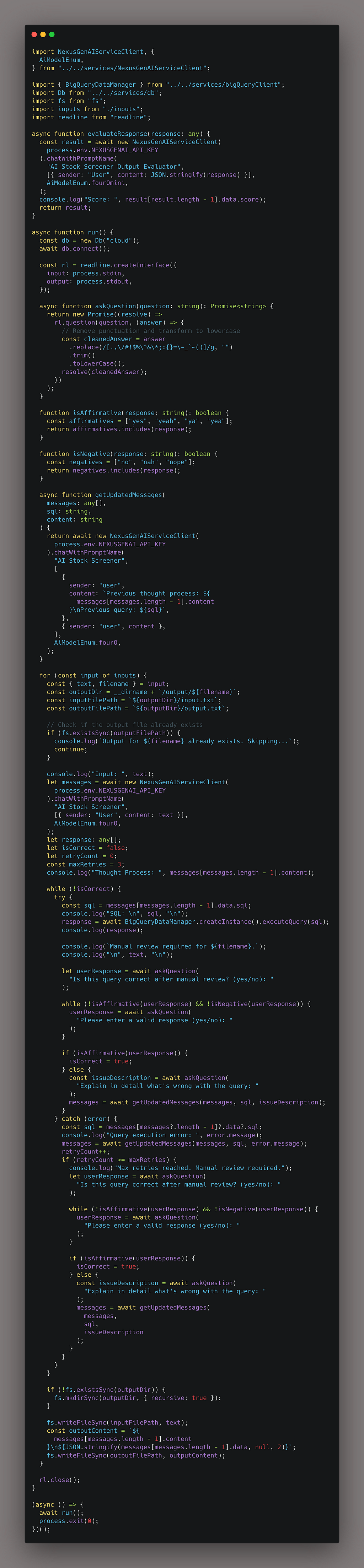
More specifically, I’m using a script to help me populate the ground truths for the model. It does the following:
- Sends the request to OpenAI
- Executes the query from the OpenAI response
- Asks the user if the output looks correct. If it doesn’t, they can add context as to why the answer looks wrong and guide the model to the right answer.
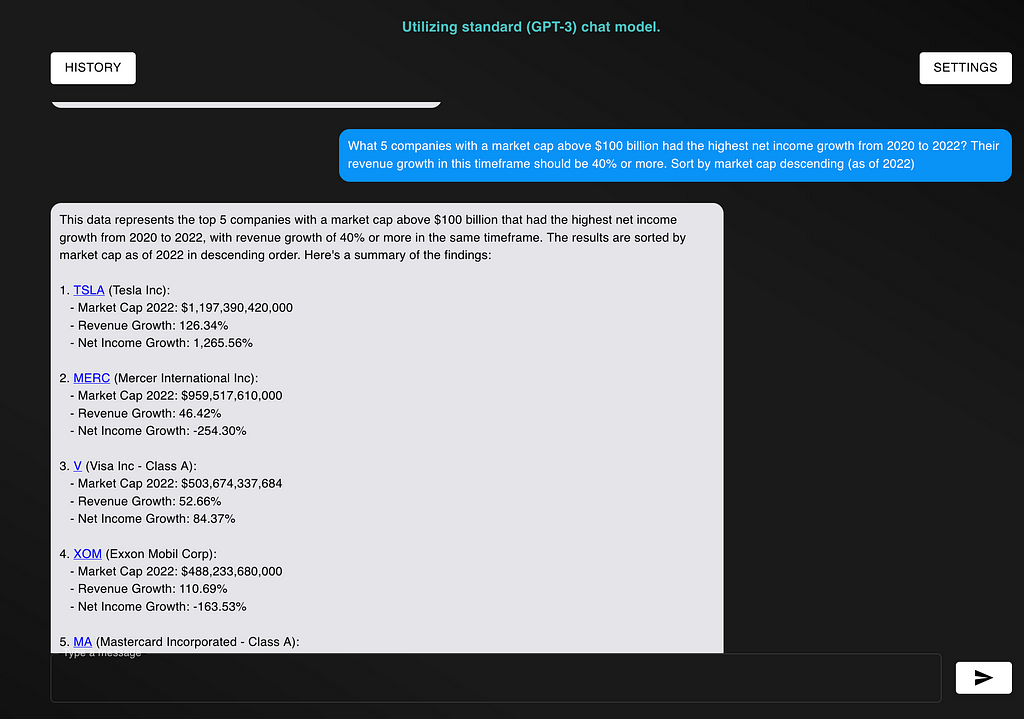
When executing the script, the output looks like the following:
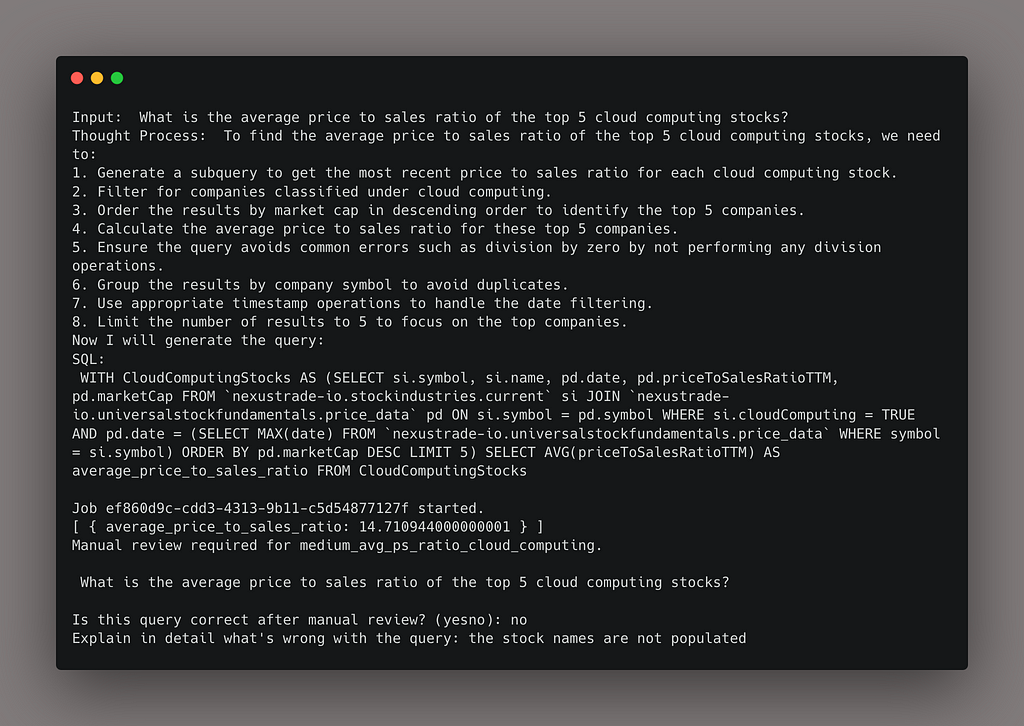
Notice that this is a semi-automated approach. Because we don’t yet have ground truths, we have to babysit the model and make sure it’s generating correct outputs. This is very important because we don’t want to optimize towards incorrect answers.
After we have our list of input/output pairs, we can move on to step 2.
Do companies that make more money have higher stock prices years later?
Data Splitting and Optimization Procedure
During this next section, I will be discussing the next phase of the optimization technique. If you’re at all familiar with training neural networks or genetic optimization, this will feel familiar to you. The procedure that I’m planning to do is as follows:
Prepare the data
Data preparation is important for eliminating bias in our results. The best way to do this is with randomization. Specifically:
- We’ll randomize our population of question/answer pairs.
- We’ll then split the data: the first 80% will be in the training set, and 20% will be the validation set.
The training set is directly used for improving the model, while the validation set is simply used to see if our optimization technique generalizes well out of sample. Our goal is that our validation set performance improves despite not training on it directly.
From Data Preparation to Initial Population Generation
Just like with genetic optimization, I’ll need to create an initial population of prompts using the training set.
Within my platform, a prompt object is more than just the system prompt that you may be used to. It is composed of the following attributes:
- The system prompt: the direct instructions that we’re giving the model
- The model: models like GPT-4o mini and Claude 3.5 Sonnet are some of the models you can use.
- Examples: Examples are what they sound like: they are examples of conversations that the model can be expected to have
The combination of everything makes up a “prompt object”. In this experiment, we won’t be attempting to optimize the model – we’ll focus on optimizing the system prompt and the examples.
Here’s how we’ll generate our initial population.
- Original Prompt Modification: Take the original prompt object and remove the existing examples.
- Prompt Variation Generation: Generate x variations of the prompt using a cost-effective model like GPT-4o mini, the newest (and least expensive) large language model that outperforms GPT-3.5 Turbo. To start, we can generate 10 variations
- Example Generation: Generate 8 random examples for each variation.
From Beaks to Bytes: Genetic Algorithms in Trading, Investing, and Finance
Evolution through survival of the fittest prompt
Next, I will optimize my prompts using a language model as an optimizer. This is one of the coolest parts about the process – each optimization component is a language model. Let me explain the process.
- Evaluation: Using GPT-4o mini as our de-facto model, we will test our initial population with a subset of examples from the training set. After getting an output, we will use a special “prompt grader” prompt to compare the output with the ground truth that we synthesized today. The prompt grader will give us a score of 0 to 1 for each prompt. We’ll then sum the scores, so each prompt will have one final score.
- Selection: We’ll perform what’s called “roulette wheel selection” to choose parents, where better-performing prompts are more likely to be chosen as parents. For each parent, we’ll randomly pick examples that will be passed on to the offspring.
- Crossover: Taking a parental pair, we will use a “prompt combiner” prompt to merge selected prompts. We’ll also combine random examples from each parent when creating our new offspring
- Mutation: To maintain variation in the population, we’ll randomly select a prompt and “mutate” it. While there are several ways we could go about this, we’ll start by using a simple “prompt mutator” prompt that just rephrases the system prompt. We can also have an “example re-arranger”, which affects the order in which examples are saved to the prompt object.
- Replacement: Finally, we’ll evaluate the performance of each of our new prompts, rank the prompts by their performance, and cull the lower-performing ones.
As you can see, this approach is fully-enabled by large language models. With the release of GPT-4o mini, it’s never been cheaper to perform this type of optimization.
The exact implementation of the “prompt grader”, “prompt combiner”, and “prompt mutator” will be given in greater detail in the following article. To summarize them, they will be their own prompts, given specialized tasks to facilitate in the optimization process.
For example, the prompt grader will be given the output of the model and the ground truth, and be told to output a number from 0 to 1, with 1 meaning the model outputted a correct response (similar to the ground truth) and 0 meaning the model outputted an incorrect response.
The prompt combiner and prompt mutator will be given similar tasks for their roles.
Launching REAL Trading for NexusTrade!
Finding our prompts with the largest beak
Finally, at the end of each loop, we’ll run the following two steps:
- Validation: Test the optimized prompts on the validation set to evaluate their accuracy when compared to the ground truth.
- Iteration: Repeat the entire process a set number of times to iteratively refine and improve the prompts. To start, we’ll just repeat the process 10 times, and see the change in the validation set performance over time
The end result should be a set of prompts that are better than the original. We’ll also have a graph to see if the training and validation set performance are indeed increasing over time. Of course, all of my results will be thoroughly documented in the next article in the series.
A step-by-step guide on how to use Aurora to create novel trading strategies
Concluding Thoughts
I have a bunch of crazy ideas on how this methodology could be improved. For example, I can perform a more complex optimization technique called multi-objective optimization, which can improve multiple factors at the same time. This includes traditional factors such as speed and cost, but also less common like the personality of the model or the tone of voice they’re using.
But first, I’m starting with the baby steps of a very simple, single-objective optimization problem. Why? Because I hate prompt engineering.
If I can prove that investing 2 hours of my time developing ground truths complete eliminates the need for me to tinker with these prompts ever again, then you bet your ass that I will cherish that investment.
So stay tuned and follow along. Who knows? Maybe I will create one of the biggest advancements in working with large language models that we’ve ever seen since the release of ChatGPT.
Thank you for reading! The prompt that I am optimizing (the AI Stock Screener) is an important feature within my platform, NexusTrade. Want to see how AI can improve your investing strategies? Create an account on NexusTrade today!
NexusTrade – AI-Powered Algorithmic Trading Platform
Follow me: LinkedIn | X (Twitter) | TikTok | Instagram | Newsletter

In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: CoFeed | Differ
- More content at PlainEnglish.io
I’m sick and tired of prompt engineering. So I’m making a prompt optimizer (Part 1) was originally published in Artificial Intelligence in Plain English on Medium, where people are continuing the conversation by highlighting and responding to this story.
* This article was originally published here