How I Wish It Was Explained to Me, the Technology behind Generative AI!

GPT (Generative Pre-Trained Transformer) or BERT (Bidirectional Encoder Representations from Transformer) are the Large Language Models (LLMs) that can generate human-like text.
That’s why it is crucial to look at the work that influenced it all, i.e., The Transformers, revolutionary technology that has transformed the way we interact with AI nowadays. If you haven’t read it yet, read it now.👈🏻
Today, we are going to understand:
- What is a LLM?
- How do it work?
- It’s Business Applications.
So, Let’s start with number 1,
What is a Large Language Model?
Well, a LLM is an instance something else, called a Foundation Model.
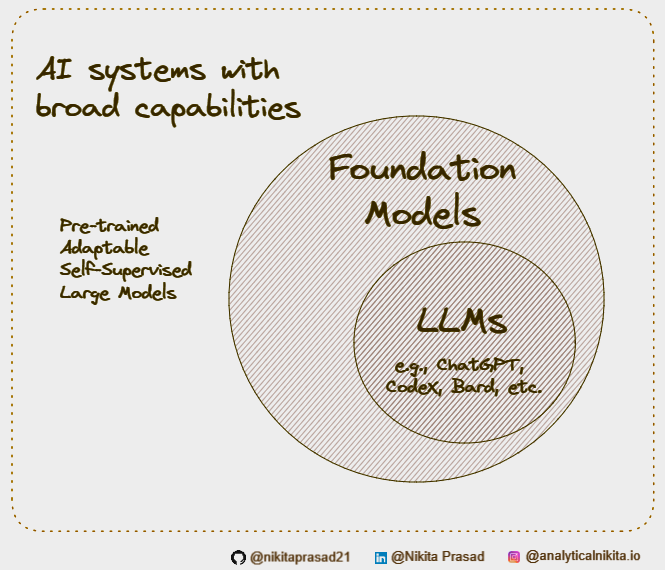
The foundational models are huge Neural Networks architectures that are Pre-Trained on large amounts of unlabeled and self-supervised data, meaning the model learns from the patterns in the data in a way that produces generalizable and adaptable output.
And large language models are instances of foundation models applied specifically to text and text-like things (such as essay, poetry, code, etc.)
Now LLM are trained on large datasets of text, such as books, articles, and bunch of publicly available sources. As the name suggests “large” i.e. the tens of gigabytes in size (parameters) and trained on enormous amounts if text data (certainly we’re talking potentially petabytes of data here.)
How many gigabytes are in a petabytes?
Well, it’s about 1 Million.
So to put that into perspective, a text file that is, let’s say one gigabytes in size that can store about 178 million tokens. Yeah, that’s truly a lot of text. And not to forget LLMs are also among the biggest models when it comes to the parameters count.
What is are the parameters?
The value of weights and biases that changes independently through back propagation as the model learns. The more parameters, the more the complexity of the model.
GPT-3 (The 3 here means that this is the Third Generation) an autoregressive language model, that produces text that looks like it was written by a human, for example, is Pre-Trained on a corpus of actually 45 terabytes of data, and it uses 175 billion ML Parameters.
Interesting right!
Alright, now comes the question regarding,
How do they work?
Well, we can think if it like this LLM equals to three things namely the components of a LLM: data, architecture and training.

Now we have already discussed the vast amounts of text data that requires to train these models.
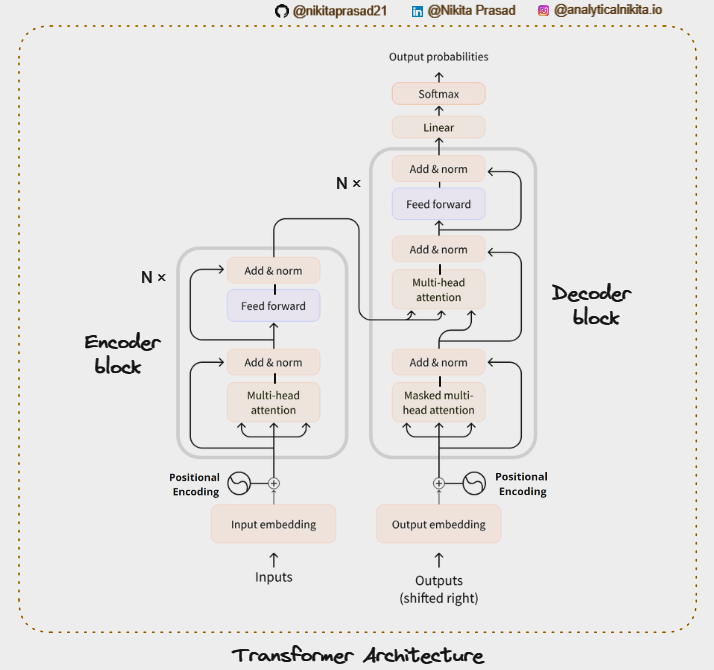
As for the architecture, for GPT-3: this is a decoder-only transformer consisting of 96 Attention blocks that each contains 96 Attention heads (Masked Multi Self Attention) and feed forward neural network layers utilize for handling sequences of data like sentences or lines of code.
The transformer are designed to understand the contextual perspective of each word in a sentence by considering it with respect to every other word.
This allows the model to build a comprehensive understanding of sentence structure and capture the contextual meaning of the word within it.
And then this architecture is trained on the large amount of data. During training the model learns to predict next word in a sentence.
You can refer to my previous article, about Self-Attention Networks to understand the intuition behind LLMs.
For instance,
The apple is …
It starts off with the random guess, maybe “The apple is purple”.
But with each iteration, the model adjusts its weights and biases to reduce the difference between its predictions and the actual outcomes, gradually improving its word predictions, until it can reliably generate coherent sentences.
Forgetting about ”purple” and learning it’s “red”.
Further the model can be fine tuned on smaller and more specific datasets as per your task, to generate more specific and accurate results.
Fine tuning allows a general purpose language model to become an expert at any specific task depending upon the use-case and the training dataset.
Okay, so let’s understand,
How does this all fit into the point number 3, The Business Applications?
Well, typically for Customer Service Applications businesses can use LLMs to create a chatbot to handle the 24*7 queries of their customers, so that human agents can look into the more complex issues.
Note: To improve the customer satisfaction, the Chatbots should respond in a human -like interactive tone, tailored to their unique needs and not in a robotic tone.
Another good field, is none other than the Content Creation domains which can use LLMs to get benefitted by generating scripts and captions for their social media posts, videos or reels, etc.
Further, LLMs are also contributing to the technology including software development and data analysis by generating and reviewing codes or even brainstorming.

Nowadays, with the continuous evolution in the LLMs we can discover them in more innovative applications such as content moderation, information retrieval, etc.
That’s why the world is going crazy about the LLMs.
Before you go… If you enjoyed this deep dive, follow me so you won’t miss out on future updates.
Clap 50 times and Share your thoughts below, if you want to see something specific or feel heard. 👇
That’s it from me. Will talk soon! 🙋🏻♀️
In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: CoFeed | Differ
- More content at PlainEnglish.io
How Large language Models work? was originally published in Artificial Intelligence in Plain English on Medium, where people are continuing the conversation by highlighting and responding to this story.
* This article was originally published here