
Frank Morales Aguilera, BEng, MEng, SMIEE
Introduction
Translating natural language into a structured query language (SQL) is critical in making data accessible to a broader audience. This capability is precious in domains where users may need to gain technical expertise to write SQL queries. The development of text-to-SQL models has thus garnered significant attention in recent years. This article presents a comprehensive evaluation of a fine-tuned text-to-SQL model, focusing on its accuracy, robustness, and potential areas for improvement.
Method
The evaluation methodology employed in this study is multi-faceted. It involves assessing the model’s performance on 100 text-to-SQL samples derived from the “gretelai/synthetic_text_to_sql” dataset. The evaluation process encompasses two primary metrics:
- Match Accuracy: This metric measures the percentage of samples where the model generates SQL queries that either exactly match or are semantically similar to the ground truth queries. Semantic similarity is determined using ChromaDB, a vector database designed for similarity search.
- Query Success Rate: This metric evaluates the percentage of semantically similar queries that execute successfully within a PostgreSQL database environment. This step is crucial as it assesses the generated SQL’s practical applicability in a real-world setting.
The evaluation script is implemented in Python and incorporates libraries like transformers, datasets, chromed, and psycopg2 for model loading, dataset handling, semantic similarity comparison, and database interaction.
Results
The evaluation results reveal a high percent match accuracy of 97% (Exact Matches plus Semantically Similar Matches, see Table 1), indicating the model’s proficiency in understanding natural language prompts and generating relevant SQL queries. This suggests that the model has been effectively fine-tuned to grasp the nuances of SQL syntax and semantics.
However, the query success rate is notably lower at 64% (see Table 1). This discrepancy is primarily attributed to schema mismatches, where the generated SQL deviates from the database schema, leading to execution errors. The analysis identifies several schema mismatches, including references to non-existent tables or columns, case sensitivity discrepancies, and formatting inconsistencies.
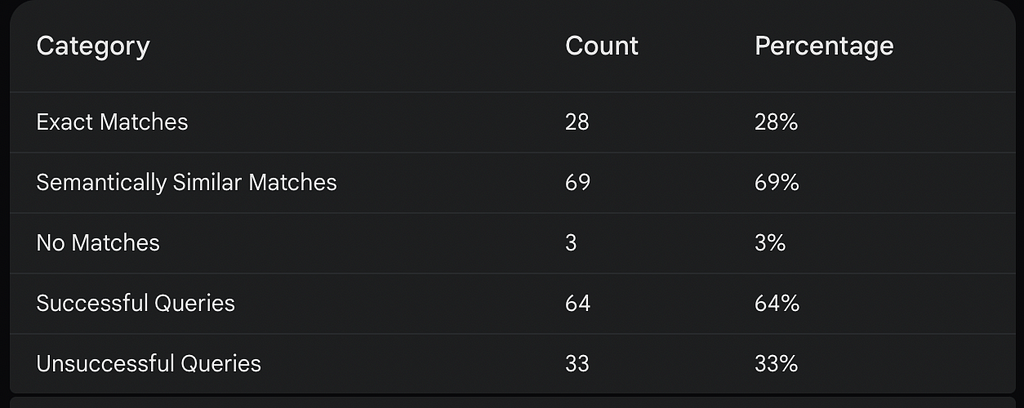
Table 1: Results
Discussion
This evaluation’s findings highlight the strengths and weaknesses of the fine-tuned text-to-SQL model. The high match accuracy demonstrates the model’s ability to comprehend natural language queries and translate them into meaningful SQL code. However, the lower query success rate underscores the challenges posed by schema mismatches, which can hinder the model’s practical utility.
The prevalence of schema mismatches suggests that the model might benefit from additional fine-tuning on a dataset that emphasizes schema variations and inconsistencies. Furthermore, incorporating schema validation and error-handling mechanisms into the model’s architecture could improve its robustness and reliability in real-world applications.
Conclusion and Future Work
In conclusion, this evaluation provides valuable insights into the performance of a text-to-SQL model fine-tuned on Mistral version 3 using the “b-mc2/sql-create-context” dataset. The high match accuracy is encouraging. Still, the lower query success rate due to schema mismatches indicates a need for further refinement. Future work should address these schema-related challenges, potentially through techniques like case-insensitive matching, flexible string matching, and pre-execution schema validation. Additionally, exploring more diverse and comprehensive evaluation datasets could provide a more nuanced understanding of the model’s capabilities and limitations.
By iteratively refining the model and incorporating robust error-handling mechanisms, we can strive towards developing text-to-SQL systems that are accurate, reliable, and adaptable to diverse database schemas.
In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: CoFeed | Differ
- More content at PlainEnglish.io
Evaluating the Performance of a Fine-Tuned Text-to-SQL Model was originally published in Artificial Intelligence in Plain English on Medium, where people are continuing the conversation by highlighting and responding to this story.
* This article was originally published here